K3S/Monitoring - A (long) way to DevSecOps - Épisode 5

Rappel de la saga : A long way to DevSecOps : Épisode 1, Épisode 2, Épisode 3, Épisode 4, Épisode 5, Épisode 6, Épisode 7, Épisode 8.
Helm
On va reparler des Charts et de Helm pour accélérer le déploiement de certains éléments. J’ai réussi à monter en compétence sur le contenu des fichiers YAML, et donc on peut passer à la vitesse supérieure. Il faut néanmoins faire attention à ce qui est « auto-magiquement » poussé dans le cluster (revoir la chaîne de confiance et toussa, toussa… bref on ne va pas se répéter…).
Je conseille de passer par une phase de compréhension des éléments contenus dans les fichiers YAML et de bien « galérer » avec kubectl, avant d’accélérer avec Helm.
Installation
Pour installer Helm sur Ubuntu 20.04, c’est assez simple on va passer par snap :
sudo snap install helm --classicIl faut ajouter dans le fichier .profile du répertoire home :
export KUBECONFIG=/etc/rancher/k3s/k3s.yaml
export PATH=$PATH:/snap/bin
source ~/.profileEt vérifier que helm accède bien au cluster K3S :
$ helm ls
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSIONAjouter le dépôt par défaut :
$ helm repo add stable https://kubernetes-charts.storage.googleapis.com/Monitoring
On va utilise Prometheus qui est incubé par la CNCF. C’est un logiciel assez prometteur (comme sont nom l’indique), il permet de stocker des métriques dans une base de données temporelle. Il va questionner des « exporters » en HTTP, puis stocke les infos en base. Grafana se charge de la visualisation. Cela permet d’avoir un ensemble plutôt léger programmé en Go.
J’apprécie aussi la couche Beats de chez Elastic, mais mon mini-cluster n’est clairement pas taillé pour accueillir une Elastic Stack (ELK).
[Nouvelle vidéo qui reprend tout ce qui est écrit ici]. Je vous invite à souscrire et à mettre un ptit pouce bleu (nous sommes restés so 2.0 avec le blogging).
Prometheus
Création de l’emplacement de travail
mkdir monitoring
cd monitoringTéléchargement des valeurs customisables (dans le fichier prometheus.yaml), puis installation (mais ne pas oublier de modifier les valeurs désirées) :
helm inspect values stable/prometheus > prometheus.yaml
helm upgrade --install prometheus -f prometheus.yaml -n monitoring stable/prometheusIl suffit de modifier les valeurs désirées dans le fichier YAML généré. Dans mon cas j’ai juste changé la classe des PVC (Persistent Volume Claim).
Grafana
helm inspect values stable/grafana > grafana.yaml (dans le fichier grafana.yaml)
helm upgrade --install grafana -f grafana.yaml -n monitoring stable/grafanaIngress
Un petit apply sur ce fichier et Grafana est accessible sur l’URL mis en paramètre.
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: ingressroutetls-grafana
namespace: monitoring
spec:
entryPoints:
- websecure
routes:
- match: Host(`grafana.example.com`)
kind: Rule
services:
- name: grafana
port: 80Pour se connecter il faut récupérer le mot de passe « admin » par défaut :
kubectl get secret --namespace monitoring grafana -o jsonpath="{.data.admin-password}" | base64 --decode ; echoSource
Première étape, ajouter la source « Pometheus » à Grafana. Dans la configuration par défaut du Chart, celui-ci est disponible au sein du cluster à l’adresse : http://prometheus-server:80
Dashboards
Il existe quelques dashboards pré-configurés pour aller plus vite, cependant il est important de passer un peu de temps pour avoir son propre dashboard, et avoir les informations désirées en tête de page.
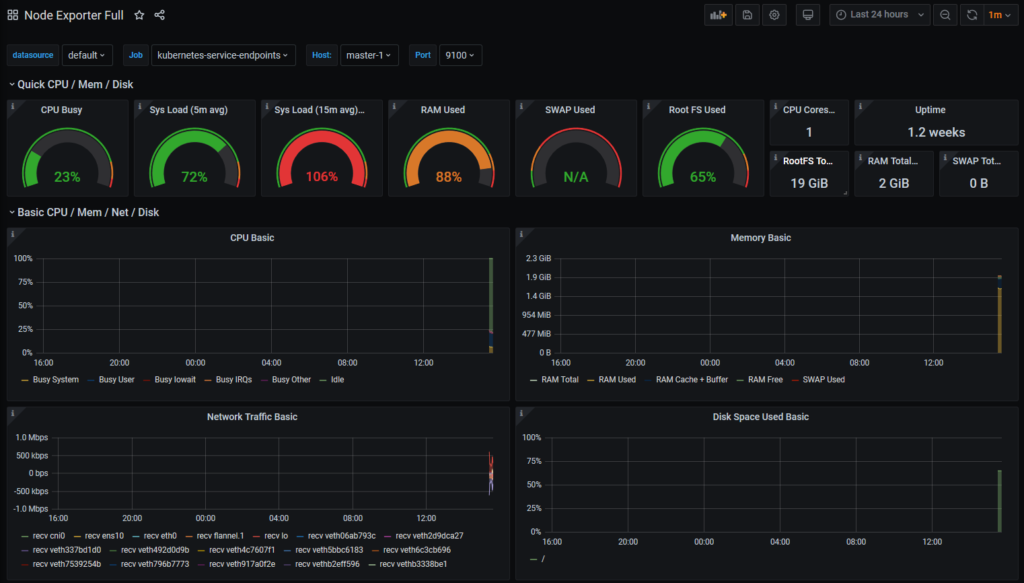
Node Exporter Full
Étape facile, il faut se connecter sur : https://grafana.example.com/dashboard/import et importer le dashboard ayant l’ID 1860.
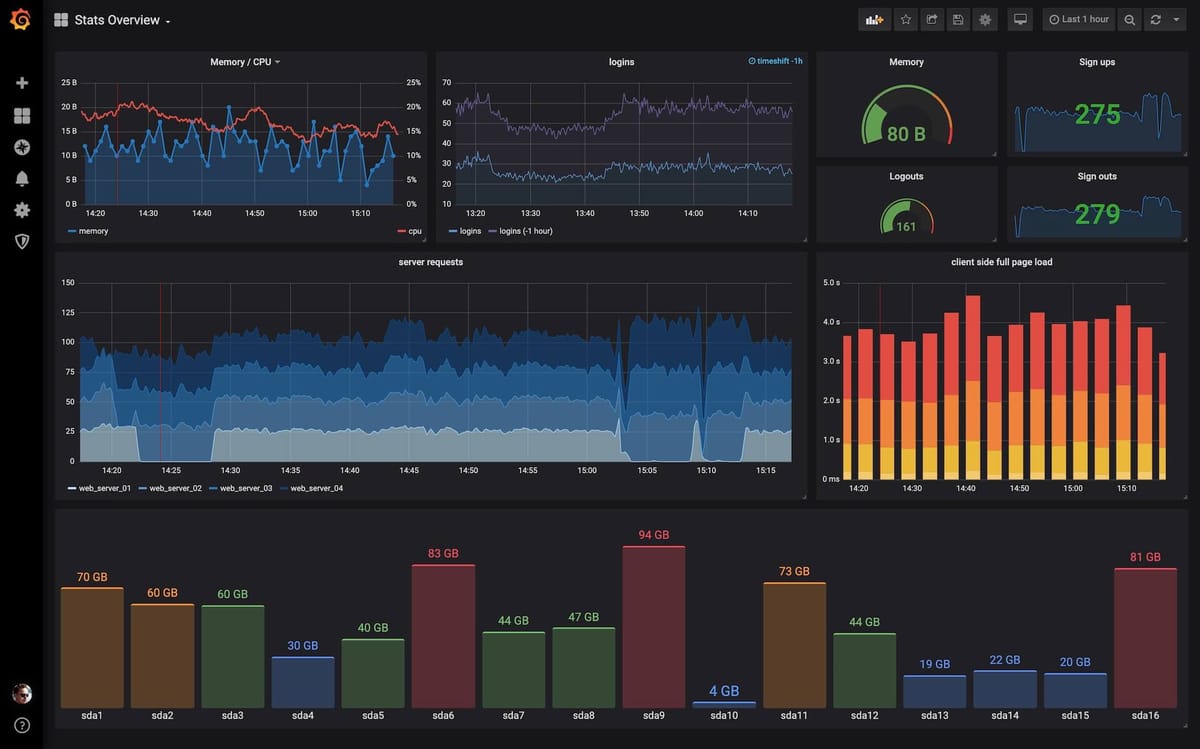
Voilà le résultat par défaut :
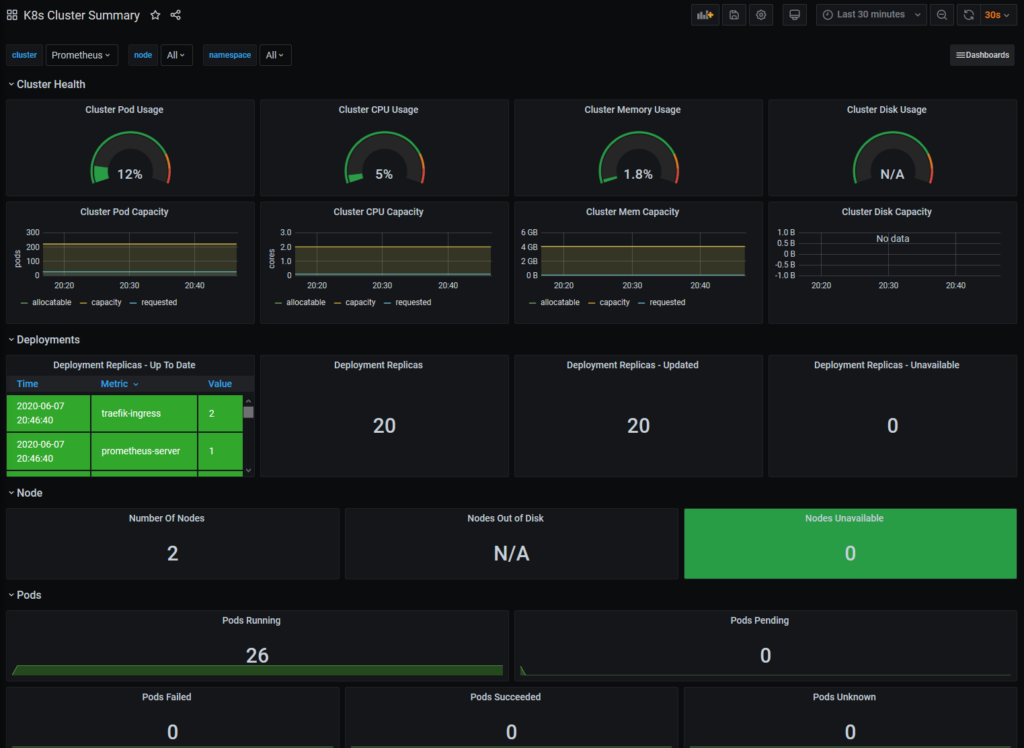
Kubernetes Dashboard
Pour ce dashboard, il faut importer l’ID 8685 :
Conclusion
Le monitoring est essentiel dans la création d’un cluster Kubernetes de production. Dans notre cas cela peut être assez limité, tant que les services restent minimaux, mais ce n’est plus totalement le cas (on voit déjà de la pression au niveau des process). Il va falloir jouer sur les paramètres d’allocation de ressources des Pods, pour que l’orchestration se passe de manière plus aisée.
